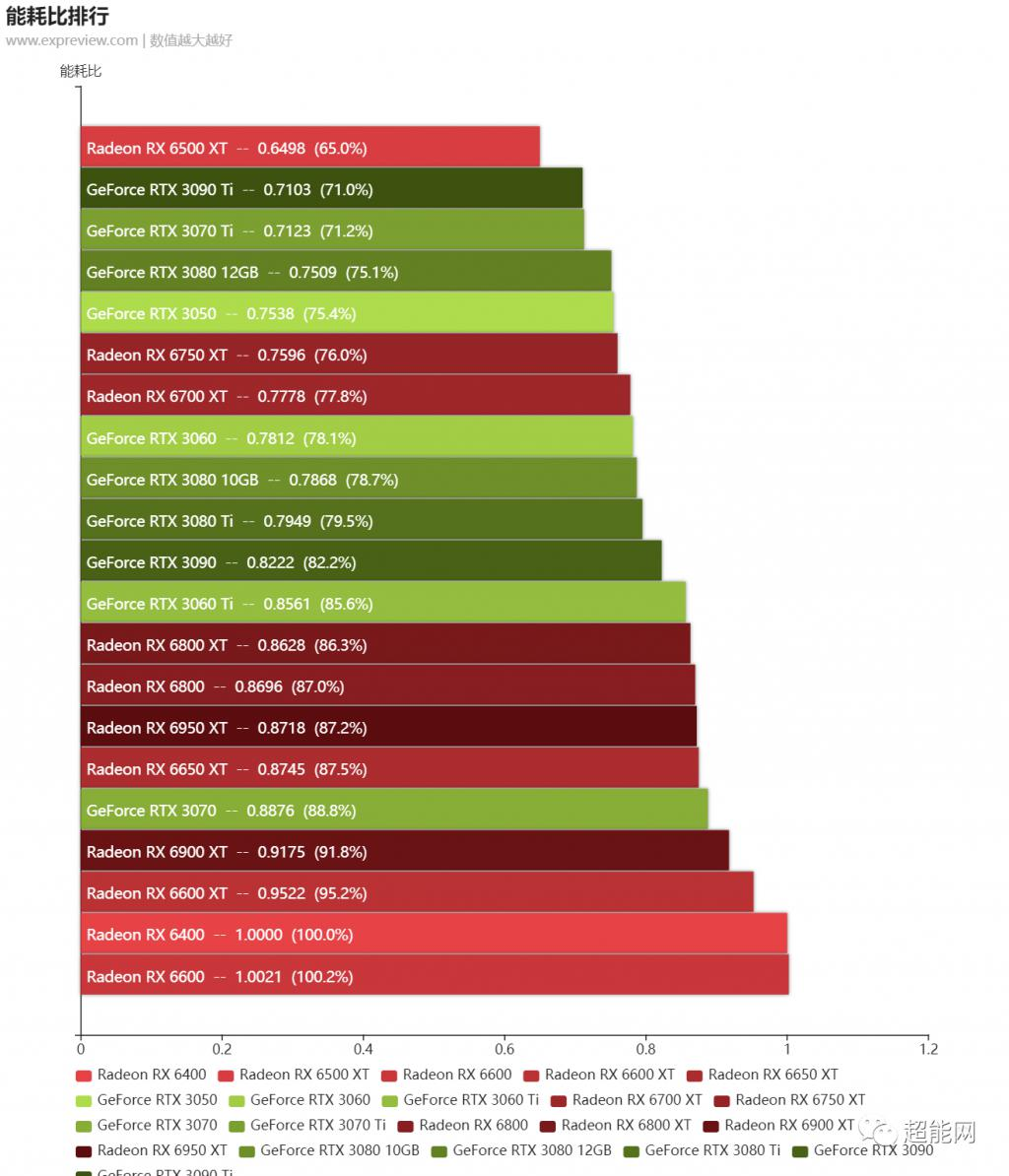
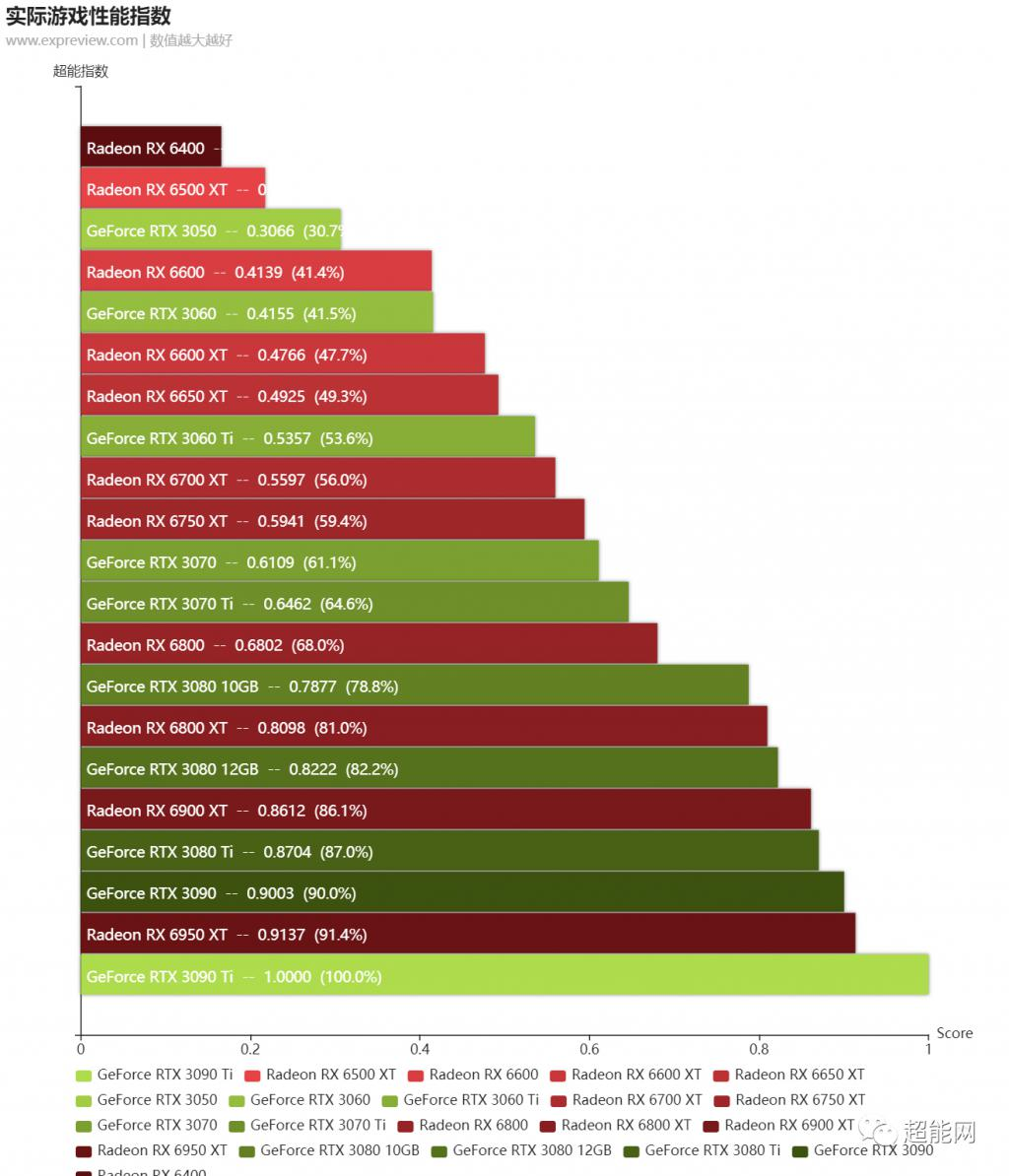
我们的读者知道,我们的阶梯列表不仅是一个排名,也是一个非常定量的数据。

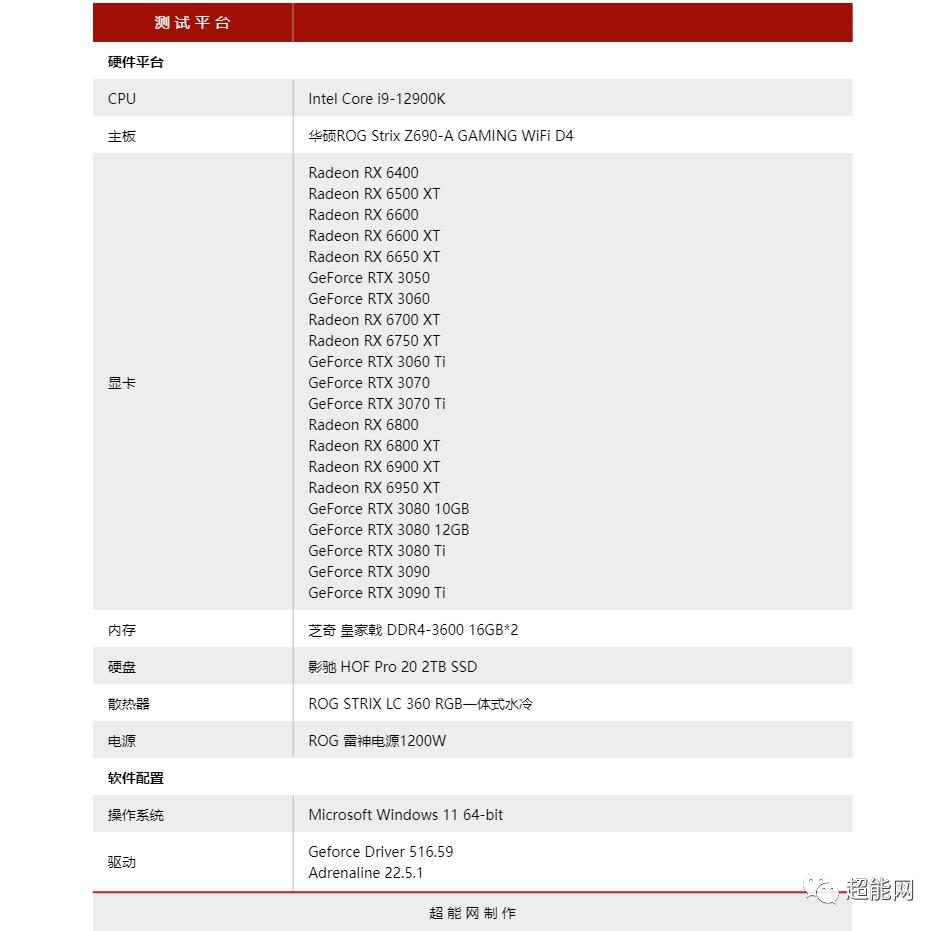
因此,这种积累将不可避免地与目前的情况略有不同。因此,在这一代显卡的NVIDIA Ampere架构显卡系列和AMD RDNA 2架构显卡系列接近尾声之际,我们将在相同的驱动程序和平台下对这些显卡进行横向评估,这不仅是对这一代竞争的总结,同时也是近期需要购买显卡的朋友的参考,毕竟,下一代显卡面临着高端卡功耗极高的问题,以及中低端卡的发布需求。许多人会在当前节点选择这一代图形卡。最后一次横向审查还用于校准我们的图形卡梯形图列表,以使其更准确。
由于我们在阶梯列表上的数据是基于传统光栅游戏的性能,因此本游戏测试仅比较传统光栅游戏性能,然后,我们将发布最新一代N卡GPU的光线追踪游戏性能的交叉评论
 SM单元的演变RTX 30系列显示卡上的SM单元比RTX 20系列上的更多。最大的变化是用于传统计算的FP32单元增加了一倍。引入第二代RT Core和第三代Tensor Core。
SM单元的演变RTX 30系列显示卡上的SM单元比RTX 20系列上的更多。最大的变化是用于传统计算的FP32单元增加了一倍。引入第二代RT Core和第三代Tensor Core。 众所周知,在图灵架构中,NVIDIA整数(INT32)和单精度浮点(FP32)数据类型被移交给两个不同的ALU进行计算。然而,FP32在现代游戏应用中最为常见。因此,为了提高计算效率,NVIDIA在NVIDIA Ampere架构上引入了一种新的ALU,它可以同时支持INT32和FP32数据类型。也就是说,有两种不同的数据路径。一个可以同时处理整数或单精度浮点计算,另一个只能处理单精度浮点运算。
众所周知,在图灵架构中,NVIDIA整数(INT32)和单精度浮点(FP32)数据类型被移交给两个不同的ALU进行计算。然而,FP32在现代游戏应用中最为常见。因此,为了提高计算效率,NVIDIA在NVIDIA Ampere架构上引入了一种新的ALU,它可以同时支持INT32和FP32数据类型。也就是说,有两种不同的数据路径。一个可以同时处理整数或单精度浮点计算,另一个只能处理单精度浮点运算。负责实时光线跟踪操作的特殊硬件单元RT Core也已在NVIDIA Ampere架构上更新到第二代。最重要的是添加了动态模糊的加速操作,以支持NVIDIA的新插值算法,这可以提高实时光线跟踪效率,同时确保动态模糊的准确性。该官员表示,速度可达上一代的8倍。
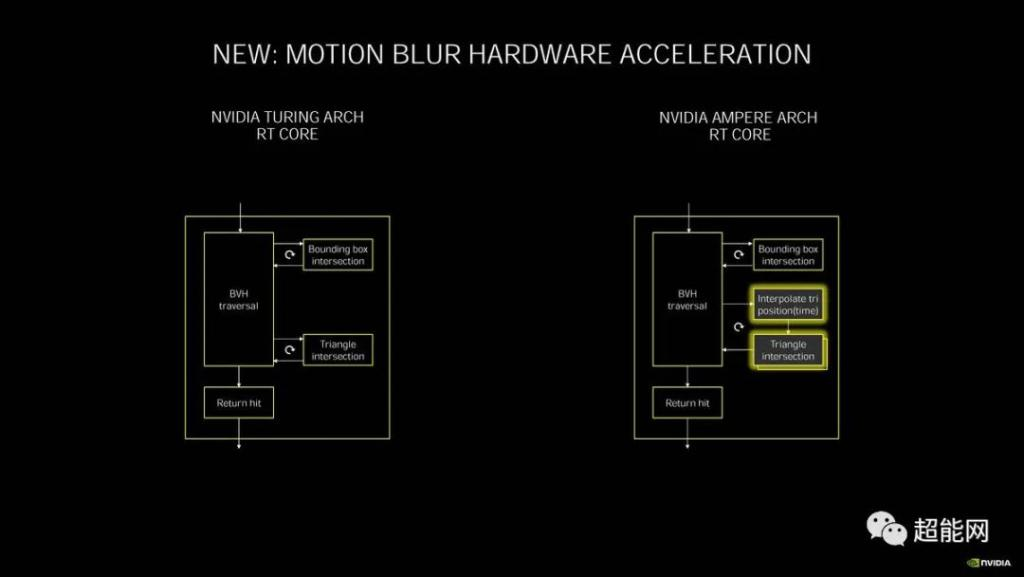
此外,在基本BVH计算方面,第二代RT内核也可以比第一代快两倍
Tensor core,负责运行AI计算的硬件单元,也已在NVIDIA Ampere架构上升级到第三代。事实上,此前发布的A100计算卡使用了新的第三代Tensor Core,其效率比第二代TensorCore高四倍,但游戏卡上的Tensor核心已在一定程度上简化,FP16 FMA计算的吞吐量仅为GA100核心Tensor的一半。

第三代Tensor Core带来的更强的人工智能计算有何用途?答案是DLSSDLSS的全称是深度学习超级采样,中文翻译为深度学习超级抽样。它的作用是通过降低游戏中的渲染分辨率来增加帧数,并通过拉伸来提高显示分辨率,例如1080P渲染分辨率和4K(2160P)显示分辨率。
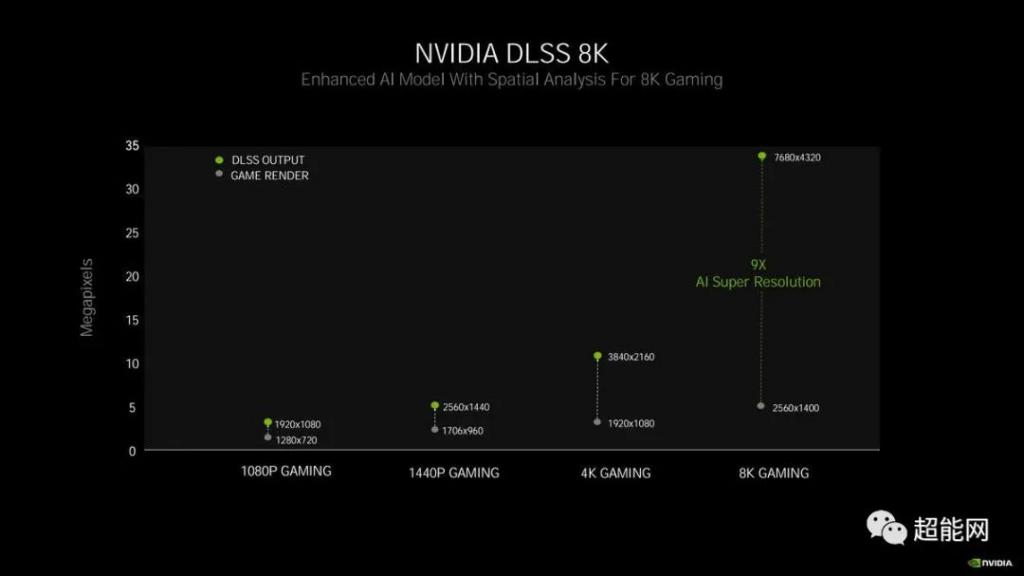
此外,从NVIDIA Volta架构开始,就采用了将不同类型的计算处理到不同的单元进行处理的想法。当时,Tensor Core引入了许多与AI相关的计算,RT Core引入了后来的分布式实时射线追踪相关计算。

然而,并非所有操作都可以在图灵GPU上并行执行。在Ampere架构上,NVIDIA提高了GPU中各个单元之间的并行性。现在,传统的计算单元、RT核心和Tensor核心可以同时工作,在原有基础上减少了帧渲染时间。
然后是HDMI 2.1,这是备受期待的新输出端口。在HDMI 2.1下,图形卡可以使用单线实现8K60Hz或4K120Hz的输出。对于那些想用大尺寸电视玩游戏的玩家来说,这对NVIDIA Reflex来说是一个好消息。

随着RTX 30系列显卡的发布,有一个新的东西对电竞游戏非常重要,或者更具体地说对电竞玩家来说,那就是NVIDIA Reflex。那幺什么是NVIDIA Reflex?事实上,它分为两部分,一部分是硬件,另一部分是软件。
硬件部分是反射延迟分析仪,它实际上可以被视为LDAT的高级版本,直接预装在显示器中。它可以用来测量玩家点击鼠标和屏幕变化之间的时间差,即整个系统的所有延迟。
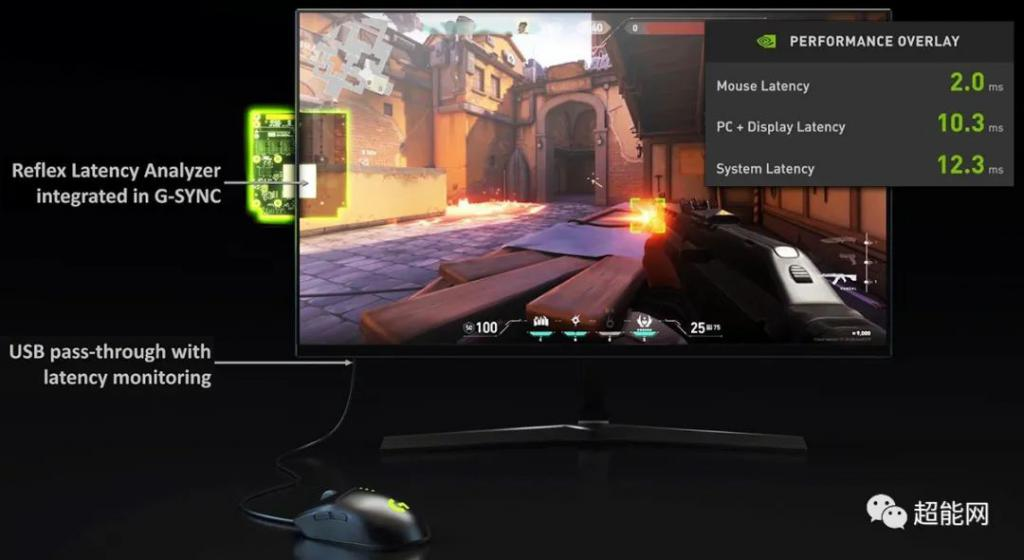
软件部分为NVIDIA Reflex SDK。NVIDIA Reflex SDK用于减少和测量渲染延迟。开发者可以直接集成到游戏中。打开低延迟模式后,他们可以将CPU与图形卡同步,显著减少渲染顺序,从而减少渲染延迟。

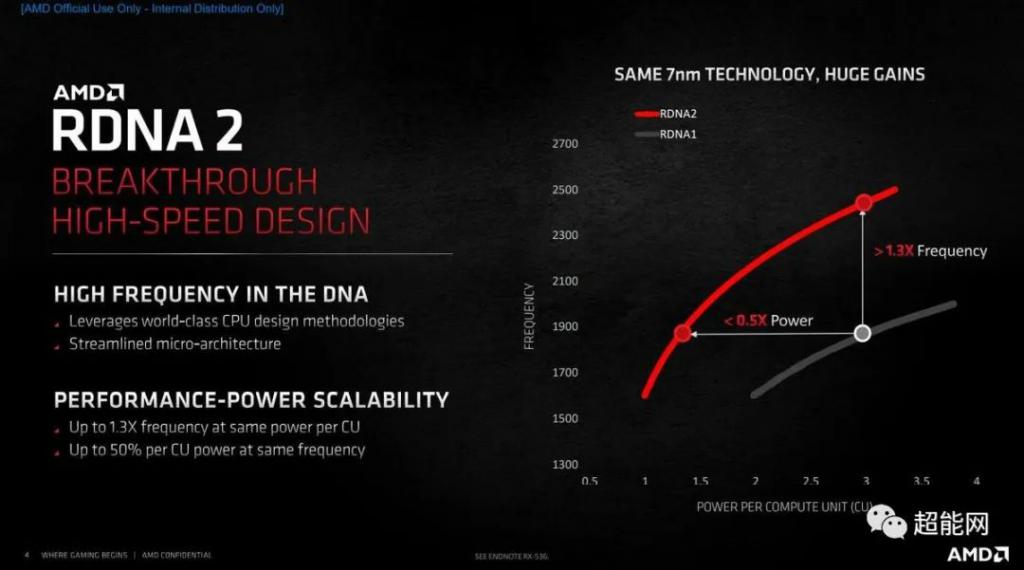
三大改进点RDNA 2架构三大改进要点:·高频设计:与RDNA 1架构相比,RDNA 2结构在相同功耗下实现了30%的最大频率增加·无限缓存设计:它可以消除带宽瓶颈,大大提高等效带宽并降低功耗,并有助于改善