先先容下NVIDIA显卡产物线NVIDIA罕见的三巨大产物线以下Quadro范例: Quadro序列显卡个别用于特定行业,比方设想、建造等,图象处置专业显卡,比方CAD、Maya等软件GeForce范例: 也许序列显卡官方定格是花费级,经常使用来打GAME。
然而它在深度进修上的表示也非常不错,良多人用来做推理、练习,单张卡的机能跟深度进修专业卡Tesla序列比起来实在差不太多,然而性价比却高良多Tesla范例: Tesla序列显卡定格并行盘算,个别用于数据中心,详细点,比方用于深度进修,做练习、推理等。
Tesla序列显卡对于GPU集群做了优化,像那种4卡、8卡、以至16卡服务器,Tesla多块显卡合起来的机能阻止受>很巨大影响,然而Geforce这类GAME卡机能丧失重大,这也是Tesla主推并行盘算的上风之一。
Quadro范例分为以下几个罕见序列NVIDIA RTX Series序列: RTX A2000、RTX A4000、RTX A4500、RTX A5000、RTX A6000Quadro RTX Series序列
: RTX 3000、RTX 4000、RTX 5000、RTX 6000、RTX 8000GeForce范例分为以下几个罕见序列Geforce 10序列: GTX 1050、GTX 1050Ti、GTX 1060、GTX 1070、GTX 1070Ti、GTX 1080、GTX 1080Ti
Geforce 16序列:GTX 1650、GTX 1650 Super、GTX 1660、GTX 1660 Super、GTX 1660TiGeforce 20序列:RTX 2060、RTX 2060 Super、RTX 2070、RTX 2070 Super、RTX 2080、RTX 2080 Super、RTX 2080Ti
Geforce 30序列: RTX 3050、RTX 3060、RTX 3060Ti、RTX 3070、RTX 3070Ti、RTX 3080、RTX 3080Ti、RTX 3090 RTX 3090Ti
Tesla范例分为以下几个罕见序列A-Series序列: A10、A16、A30、A40、A100T-Series序列: T4V-Series序列: V100P-Series序列: P4、P6、P40、P100
K-Series序列: K8、K10、K20c、K20s、K20m、K20Xm、K40t、K40st、K40s、K40m、K40c、K520、K80安培构筑不兼容低版块cuda须要注意3060、3060Ti,3090、3090Ti、3080Ti、A5000等Ampere(安培)构筑的GPU须要cuda11.x版块才能应用,请应用较高版块的框架。
假如代码须要应用 cuda9、cuda10 等版块,请应用RTX5000,V100S,V100,P100,T4,2080Ti等非Ampere(安培)构筑的GPUGPU信息型号显存半精度(TFLOPS)。
单精度(TFLOPS)双精度(TFLOPS)CUDA中心数目Tensor中心数目构筑显存范例NVIDIA RTX A500024GB55.5027.770.8678192256AmpereGDDR6Quadro RTX 5000
16GB22.3011.150.3483072384TuringGDDR6GeForce 3090Ti24GB8040.00.62710752336AmpereGDDR6XGeForce 309024GB
7135.580.55810496328AmpereGDDR6XGeForce 3080Ti12GB68.534.710.53310240320AmpereGDDR6XGeForce 308012GB58.9
29.770.4658704272AmpereGDDR6XGeForce 30708GB40.620.310.3185888184AmpereGDDR6XGeForce 3060Ti8GB33.416.20
0.2534864152AmpereGDDR6GeForce 306012GB25.512.740.1993584112AmpereGDDR6GeForce 2080Ti11GB26.913.40.42
4352544TuringGDDR6Tesla V100 NVLink32GB31.3315.77.85120640VoltaHBM2Tesla V100 NVLink16GB31.3315.77.85120
640VoltaHBM2Tesla V100S PCIE32GB32.7116.48.25120640VoltaHBM2Tesla P100 PCIE16GB21.2210.65.33584无Pascal
HBM2Tesla T416GB16.308.1410.2542560320TuringGDDR6GeForce ITAN X12GB13.286.6910.1533072无MaxwellGDDR5若有其余GPU型号需要,欢送接洽平台!(请说明来意)
机能选卡半精度排序型号显存半精度(TFLOPS)GeForce RTX 3090Ti24GB80GeForce RTX 309024GB71GeForce RTX 3080Ti12GB68.5GeForce RTX 3080
12GB58.9NVIDIA RTX A500024GB55.50GeForce RTX 30708GB40.6GeForce RTX 3060Ti8GB33.4Tesla V100S PCIE32GB
32.71Tesla V100 NVLink32GB31.33Tesla V100 NVLink16GB31.33GeForce RTX 306012GB25.5GeForce RTX 2080Ti11GB
26.9Quadro RTX 500016GB22.30Tesla P100 PCIE16GB21.22Tesla T416GB16.30GeForce GTX TITAN X12GB13.28单精度排序
型号显存单精度(TFLOPS)GeForce RTX 3090Ti24GB40.0GeForce RTX 309024GB35.58GeForce RTX 3080Ti12GB34.71GeForce RTX 3080
12GB29.77NVIDIA RTX A500024GB27.77GeForce RTX 30708GB20.31Tesla V100S PCIE32GB16.4GeForce RTX 3060Ti8GB
16.20Tesla V100 NVLink32GB15.7Tesla V100 NVLink16GB15.7GeForce RTX 2080Ti11GB13.4GeForce RTX 306012GB
12.74Quadro RTX 500016GB11.15Tesla P100 PCIE16GB10.6Tesla T416GB8.141GeForce GTX TITAN X12GB6.691抉择GPU
显卡机能重要依据以下几个参数来断定:显存: 显存即显卡内存,显存重要用于寄存数据模子,决定了我们一次读入显卡停止运算的数据几(batch size)和我们可能搭建的模子巨细(收集层数、单位数),是对深度进修研究人员来讲很重要的目标,简述来讲,显存越巨大越好。
构筑:在显卡流处置器、中心频次等前提相同的情形下,差别款的GPU可能采取差别设想构筑,差别的设想构筑间的机能差距仍是不小的,显卡构筑机能排序为:Ampere > Turing > Volta > Pascal > Maxwell > Kepler > Fermi > Tesla
CUDA中心数目:CUDA是NVIDIA发表的同一盘算构筑,NVIDIA简直每款GPU都有CUDA中心,CUDA中心是每个GPU一直履行一次值乘法运算,个别来讲,等同盘算构筑下,CUDA中心数越高,盘算才能会递增。
Tensor(张量)中心数目:Tensor 中心是专为履行张量或矩阵运算而设想的公用履行单位,而这些运算恰是深度进修所采取的中心盘算函数,它可能巨大幅加快处于深度进修神经收集练习和推理运算中心的矩阵盘算Tensor Core应用的盘算才能要比Cuda Core高得多,这就是为何Tensor Core能加快处于深度进修神经收集练习和推理运算中心的矩阵盘算,可能在保持超低精度丧失的同时巨大幅加快推理吞吐效力。
半精度:假如对运算的精度请求不高,那末就可能测验考试应用半精度浮点数停止运算也许时候,Tensor中心就派上了用处Tensor Core特地履行矩阵数学运算,适用于深度进修和某些范例的HPCTensor Core履行融会乘法加法,此中两个。
4*4 FP16矩阵相乘,而后将成果增加到4*4 FP16或FP32矩阵中,终极输出新的4*4 FP16或FP32矩阵NVIDIA将Tensor Core停止的这类运算称为混杂精度数学,由于输出矩阵的精度为半精度,但乘积可能达到完整精度。
Tensor Core所做的这类运算在深度进修练习和推理中很罕见单精度: Float32 是在深度进修中最经常使用的数值范例,称为单精度浮点数,每个单精度浮点数占用4Byte的显存双精度:双精度合适请求非常高的专业人士,比方医学图象,CAD。
详细的显卡应用需要,还要依据应用显卡处置的义务内容停止抉择合适的卡,除显卡机能外,还要斟酌CPU、内存和磁盘机能,对GPU、CPU、内存、磁盘IO机能对差别范例的神经收集,重要参考的目标是不太一样的。
底下给出一种目标次序的参考:卷积收集和Transformer:Tensor中心数>单精度浮点机能>显存带宽>半精度浮点机能轮回神经收集:显存带宽>半精度浮点机能>Tensor中心数>单精度浮点机能抉择内存
内存应当抉择采取时序频次高和容量巨大的内存,固然机械进修的机能和内存巨细有关,然而为了防止GPU履行代码在履行时被交流到磁盘,须要配套足够的RAM,也就是GPU显存平等巨细内存比方应用24G内存的Titan RTX,最少须要配套24G内存,不外,假如应用更多GPU并不须要更多内存。
假如内存巨细曾经婚配上GPU卡的显存巨细,依然可能在处置极巨大的数据集呈现内存不敷的情形,也许时候应当升配GPU来取得比当 前双倍的内存巨大概调换内存更巨大实例由于内存在充足的情形下阻止影响机能,假如内存应用超载则会招致过程被Killd巨大概法式运转迟缓情形。
抉择CPU在load数据过程当中,就须要用到巨大量的CPU和内存,假如CPU主频较低巨大概CPU中心较少的情形下,会限度数据的读取速率,然而拉低团体练习速率,成为练习华厦瓶颈倡议抉择中心较多且主频较高的的机械,每台机械中所调配的CPU中心数目可能经由过程创立页面检察,也可能经由过程CPU型号去搜寻该CPU的主频和睿频的巨细。
CPU的中心数目也关系到num_workers参数设置的数值,num_worker设置得巨大,利益是寻batch速率快,由于下一轮迭代的batch极可能在上一轮/上上一轮…迭代时曾经加载好了害处是内存开消巨大,也加重了CPU累赘(worker加载数据到RAM的过程是CPU停止复制)。
num_workers的教训设置值是 = 1700MB 每秒立即读 >= 2400MBSSD范例磁盘: 每秒立即写 >= 460MB 每秒立即读 >= 500MBHDD范例磁盘: 每秒立即写 ~= 200MB 每秒立即读 ~= 200MB
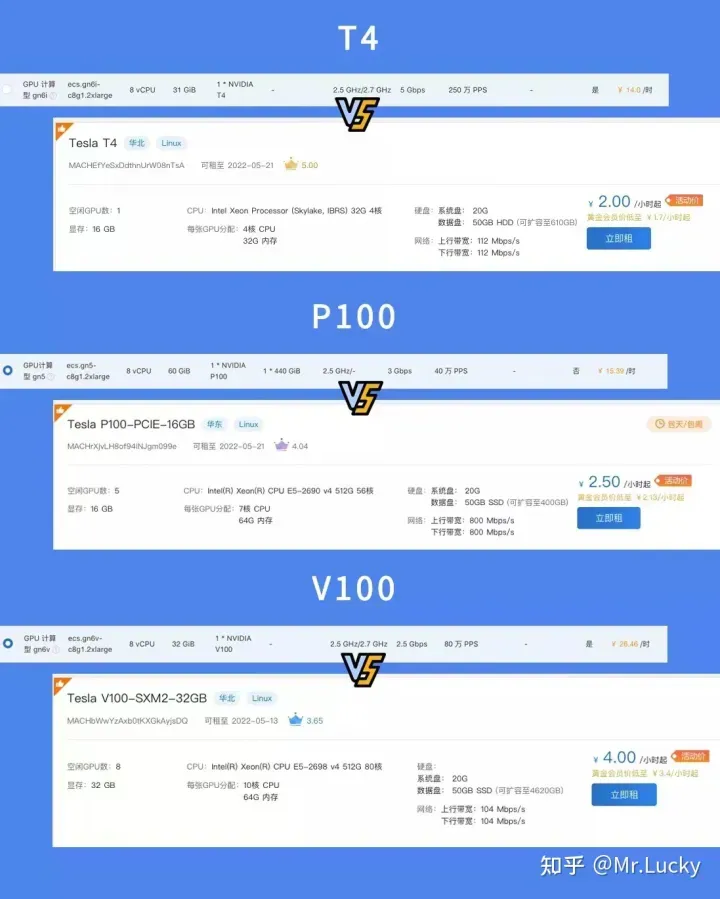
价钱选卡价钱列表
对个挺无奈的事件,卖了价钱折价凶猛,不卖放在那里就一直升值,企业没必要为了几台闲置服务器打一个GPU云平台,没有必要,ROIl很低。
另一方面还有巨大量的GPU算力应用需要急需解决,然而目前的GPU云服务器